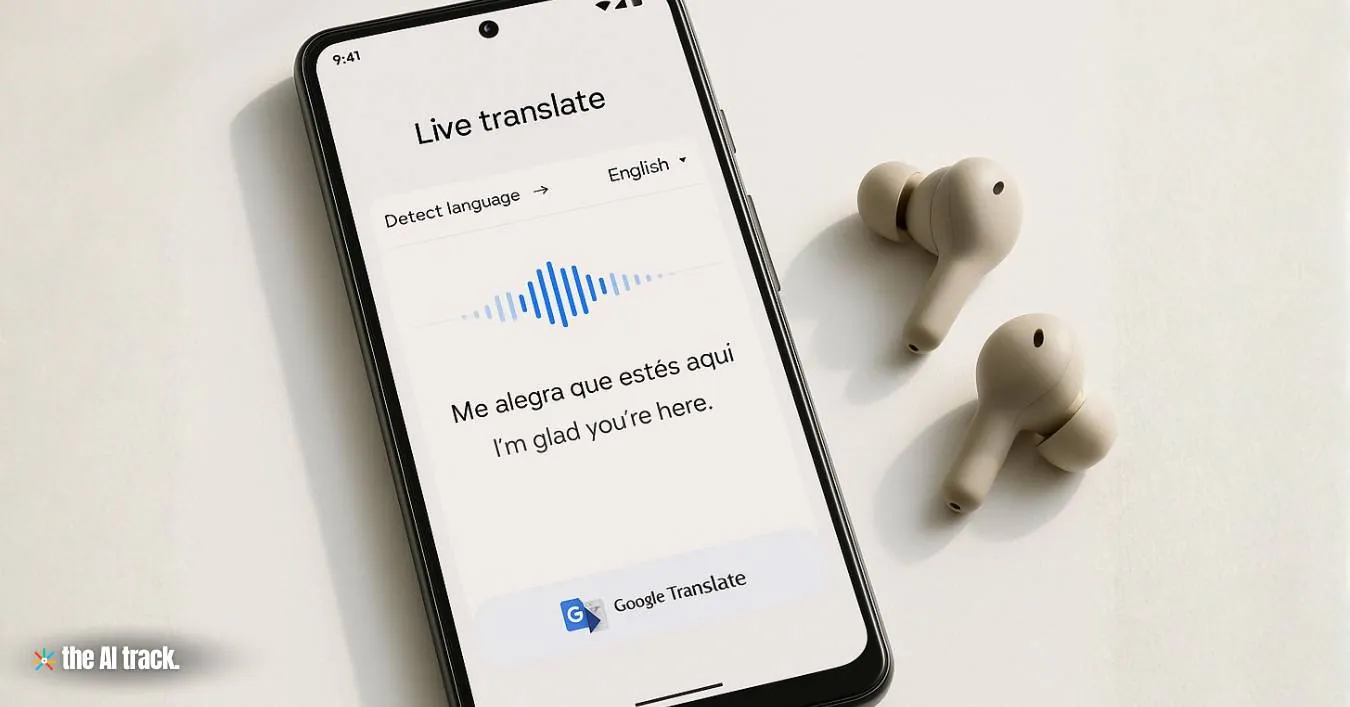
谷歌推出支持70余种语言的实时语音翻译功能
谷歌 于周二发布了 Gemini 3.5 Live Translate——一款由 AI 驱动的音频模型,可近乎实时地在70余种语言之间翻译语音,标志着该公司在设备端翻译技术方面迈出了迄今最具雄心的一步。同日,Google DeepMind 推出了实验性开放模型 DiffusionGemma,该模型将扩散技术应用于 Gemma 4 架构,文本生成速度最高可达标准自回归模型的四倍。
打破语言壁垒
Gemini 3.5 Live Translate 有别于传统的逐句翻译系统——后者需要等说话者说完一句才能输出译文。这款模型能够持续处理并翻译语音,仅比说话者滞后数秒,同时保留原有的语调、节奏和音调。
该模型正在向三个平台推出:面向全球用户,在 Android 和 iOS 版 Google 翻译应用上线;面向开发者,通过 Gemini Live API 和 Google AI Studio 开放公开预览;面向特定 Google Workspace 企业客户,从本月起在 Google Meet 上进入私测阶段。Meet 的集成将语音翻译支持的语言从此前的 5 种扩展至逾 70 种,单次会议可实现超过 2,000 种语言组合的互译。
Android 新增的"聆听模式"让用户无需耳机,只需像接听普通电话一样将设备贴近耳朵,即可通过听筒收听翻译内容。所有生成的音频均经过 SynthID 水印标记,以便识别 AI 生成内容。
DiffusionGemma:通过扩散实现文本生成
另外,谷歌 DeepMind 发布了 DiffusionGemma——一个拥有 260 亿参数的混合专家模型。它生成文本的方式类似于图像扩散模型生成图片:从噪声出发,并行地对最多 256 个 token 的整个块进行逐步精炼,而非逐词预测。
DiffusionGemma 基于 Gemma 4 架构构建,推理时仅激活 38 亿个参数,在单块英伟达 H100 GPU 上可达每秒超过 1,000 个 token 的生成速度,在消费级 GeForce RTX 5090 上也可达约每秒 700 个 token。模型权重已在 Hugging Face 上以 Apache 2.0 开源许可证发布。
谷歌 CEO 桑达尔·皮查伊在社交媒体上着重介绍了 DiffusionGemma,称其为"一匹推理速度提升最高达 4 倍的千里马",标志着公司的文本扩散研究正式融入 Gemma 4 家族。
速度与质量的权衡取舍
谷歌提醒用户,DiffusionGemma 目前仍处于实验阶段,在输出质量基准测试上落后于标准 Gemma 4,因此主要推荐将其用于对速度要求较高的本地工作流,例如内联编辑、快速迭代和智能体循环,而非需要追求极致质量的生产环境部署。英伟达已针对旗下全系硬件对该模型进行了优化,覆盖从消费级 GPU 到 DGX Spark 系统,并在 vLLM、Hugging Face Transformers 和 Unsloth 中提供了首日支持。